

If you have a few years of experience in the DevOps ecosystem, and you're interested in sharing that experience with the community, have a look at our Contribution Guidelines.
1. Overview
Apache Kafka is an open-source distributed event streaming platform. The distributed architecture of Kafka makes it highly scalable, available, and fault-tolerant. At its core, Kafka uses the concept of the append-only log which sequentially writes messages into the end of a log file. Due to the sequential write, Kafka can offer a high write throughput as it accesses the disk sequentially. However, the sequential write design makes it difficult for Kafka to provide out-of-the-box support for message prioritization.
In this tutorial, we’ll learn two strategies we can employ to implement message prioritization with Apache Kafka.
2. Message Prioritization
In the context of the messaging system, message prioritization refers to assigning different levels of importance to messages being processed. For example, the messages in a financial system typically have different priorities. We might want to label fraud alerts and payment confirmations with higher priority than promotional notifications.
The goal is to ensure messages with higher priority always take precedence over messages with lower priority if there’s a queue or contention.
In most message queuing systems, there is a message priority support, For example, the RabbitMQ’s priority queue ensures messages in the priority queues are delivered before the message from other non-priority queues.
3. Challenges With Message Prioritization in Kafka
Apache Kafka doesn’t provide the message priority semantic out of the box. There’s no built-in support for labeling a message as a higher priority than the other and expecting the message brokers to treat it differently. This poses a challenge when a single topic contains messages of different priority.
To illustrate the problem, let’s consider a hypothetical scenario in a financial system. The system has three different message types: fraud alert, transfer notification, and promotional alert. The message types are listed according to their order of urgency with the fraud alert being the most important.
When we share the same topic for these messages, the latency for handling the high-priority message highly depends on the traffic of the other messages in the same topic. When the frequency of the promotional alerts is much higher than the fraud alerts, it impairs the fraud alert processing’s latency.
Consider the distribution of the message types in our topic:
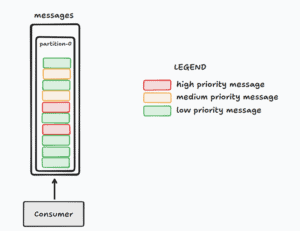
The illustration shows that all the messages on the same topic are queueing up according to their insertion order in partition 0. Given the sequence of messages, the consumer is forced to process the three lower-priority messages first before they can handle the high-priority message.
Fortunately, there are two strategies we can employ to overcome this problem.
4. Topics by Priority
The first strategy for implementing message prioritization in Apache Kafka is to create different topics for different priorities. Then, the producer is responsible for writing messages on the respective topics depending on the priority. Subsequently, we can deploy different consumer groups for the different topics.
Continuing from our problem, we can create three topics to store messages with different priorities: message-high, message-medium, and message-low:
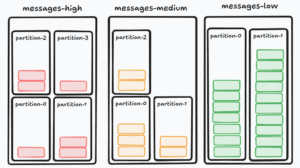
Thanks to the separation of topics, this approach effectively avoided the problem of lower-priority messages blocking the higher-priority messages.
Besides that, this setup allows us to be more effective in allocating resources depending on the needs. For example, we can give the topics with higher priority more partitions as the number of partitions directly affects the number of parallelisms the consumers can afford.
Additionally, the topic separation strategy allows for more fine-grained monitoring and management policies depending on the priority. For example, we can set stricter SLAs and alerting mechanisms for the high-priority message topic.
5. Bucket Priority Pattern
The Bucket Priority Pattern is a pattern for implementing message prioritization on the partition level. Contrary to the first approach, the Bucket Priority pattern uses multiple partitions of a single topic to queue messages for different priorities.
5.1. How it Works?
On a high level, the Bucket Priority Pattern works by grouping partitions of a topic into several groups, also known as buckets, for different priorities. Specifically, the partitions are grouped so that the higher-priority group would have more partition counts than the lower-priority group. This ensures more parallelism for the higher priority messages as the number of partitions of a topic directly affects the number of consumer parallelisms.
Then, the message key serves as the bucket indication. The BucketPriorityPartitioner inspects the message key to figure out the bucket it belongs to and then routes it accordingly.
The consumer can then selectively process a specific bucket in the topic using the BucketPriorityAssignor. This ensures that the consumer is focused on processing messages from a specific bucket.
5.2. Producer Configuration
We’ll first need to configure our producer to use the BucketPriorityPartitioner class as the partitioner:
Properties configs = new Properties();
configs.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,
BucketPriorityPartitioner.class.getName());
KafkaProducer<K, V> producer = new KafkaProducer<>(configs);Then, we specify the topic that we want its partitions to be grouped into buckets for prioritization purposes. To do that, we can use the BucketPriorityConfig.TOPIC_CONFIG key:
configs.setProperty(BucketPriorityConfig.TOPIC_CONFIG, "messages");Subsequently, we specify the type of buckets we have using the BUCKETS_CONFIG and their respective allocations using the ALLOCATION_CONFIG:
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "high", "medium", "low");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "60%", "30%", "10%");Critically, the values in the ALLOCATION_CONFIG must sum to 100% and its length must correspond to the length of the BUCKETS_CONFIG. Failure to comply with the constraints causes a runtime error when we start the producer.
5.3. Consumer Configuration
On the consumer side, we’ll pass several BucketPriorityConfig configurations to the consumer. Let’s create a consumer that consumes from the high bucket from our message topic.
Firstly, we configure the consumer’s partition assignment strategy as the BucketPriorityAssignor as the partition assignment:
Properties configs = new Properties();
configs.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
BucketPriorityAssignor.class.getName());
KafkaConsumer<K, V> highPriorityMessageConsumers = new KafkaConsumer<>(configs);The BucketPriorityAssignor is a priority bucket-aware assignor. Specifically, the BucketPriorityAssignor is an assignor that considers the grouping of the partitions as buckets and ensures the consumers do not get assigned irrelevant buckets from the same topic.
Next, we’ll need to replicate the configuration of the buckets to our consumer groups. This allows the assignor to know how the partitions of the topic are being grouped into buckets. Concretely, we’ll configure the TOPIC_CONFIG, BUCKETS_CONFIG, and ALLOCATION_CONFIG exactly like what we pass to the producer’s configuration:
configs.setProperty(BucketPriorityConfig.TOPIC_CONFIG, "messages");
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "high", "medium", "low");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "60%", "30%", "10%");Now, we specify the bucket the consumer will be consuming from using the BUCKET_CONFIG key:
configs.setProperty(BucketPriorityConfig.BUCKET_CONFIG, "high");With this configuration, our consumer listens to the messages topic, but will only consume messages from partitions that belong to the high bucket.
5.4. Publishing Messages
To publish the message into the specific bucket, we must match the message’s key to the bucket name. For example, we can publish a message to the high bucket by setting the message key to high:
// Define the key and message
String key = "high";
String message = "{\"event\": \"FraudAlert\", \"id\": 1, \"userId\": 1}";
// Create a producer record
ProducerRecord<String, String> record = new ProducerRecord<>("messages", key, message);
// Send the message
producer.send(record);
The rules on the message key are that the bucket name must appear as the first part of the message key string separated by the hyphen (-) delimiter. In other words, we can have message key values like high-001 and high-01901b2e-e5d3-7b5a-95da-d55947d80ce4, as long as the bucket name is the first part of the message key.
6. Conclusion
In this tutorial, we’ve learned that Apache Kafka does not support message prioritization out of the box. Then, we’ve explored two approaches to implementing message prioritization in Kafka. The first approach creates different topics for different priority classes. This approach is the simplest to set up and offers great flexibility in resource allocation. However, there is more operational complexity in return as there are more topics to look after in a cluster.
The second approach uses the Bucket Priority Pattern that prioritizes messages on the partition level. This approach allows us to use the same Kafka topics for all the messages with different priorities.